DFM Data: A Composite Dataset for Danish LLMs.¶
This page provides a detailed description of the composite dataset used to train large language models developed by Danish Foundation Models. The dataset is curated to offer a diverse and comprehensive corpus across multiple domains, including legal, financial, and literary texts, with the primary intention of developing language models for Danish.
Dataset Description¶
Summary¶
The DFM Data is a collection of datasets used for Danish Foundation Models. This repository ensure documentation to data along with FAIR data practices.
Curation Rationale¶
These datasets were collected and curated with the intention of developing language models for Danish.
Data Collection and Processing¶
The dataset was constructed by collecting and integrating text from a wide variety of public and partner-provided sources. The raw data was subjected to a standardized cleaning pipeline, which included steps such as deduplication, filtering of low-quality content to prepare it for large-scale language model training.
Dataset Statistics¶
- Number of samples: 230.07M
- Number of tokens (Llama 3): 430.24B
- Average document length in tokens (min, max): 1.87K (1, 51.77M)
The following plot pr. dataset histograms displaying document lengths.

Languages¶
This dataset includes the following languages:
- Danish
- English
- Swedish
- Norwegian Bokmål
- Norwegian Nynorsk
Below is a visualisation of the main languages in each of the datasets.

Domains¶
This dataset consist of data from various domains (e.g., legal, books, social media). The following table and figure give an overview of the relative distributions of these domains.
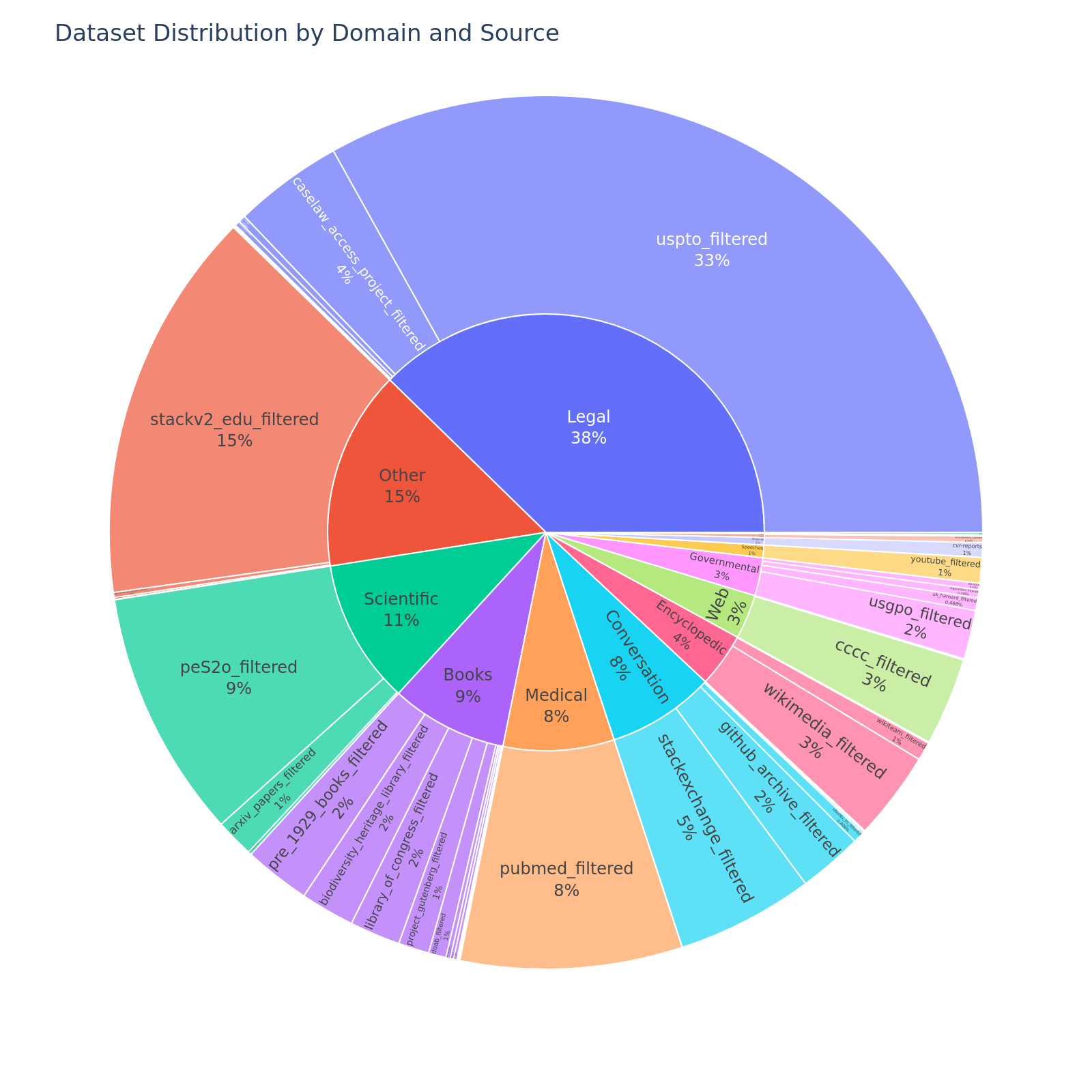
Licensing¶
The following gives an overview of the licensing in the DFMv1. To get the exact license of the individual datasets check out the individual datasets by clicking the links in the table. These license is applied to the constituent data, i.e., the text. The collection of datasets (metadata, quality control, etc.) is licensed under CC-0.
Additional Information¶
Citation Information¶
If you use a model trained on this dataset, please cite the associated DFM project or research paper when it becomes available. A BibTeX entry will be provided here upon the official release of a corresponding paper.
Disclaimer¶
We do not own any of the text from which the data has been extracted. If you believe that we are not allowed to train on any of the datasets noted please do contact us.
Notice and take down policy¶
Notice: Should you consider that our data contains material that is owned by you and should therefore not be included in the training of LLMs here, please:
- Clearly identify yourself, with detailed contact data such as an address, telephone number or email address at which you can be contacted.
- Clearly identify the copyrighted work claimed to be infringed.
- Clearly identify the material that is claimed to be infringing and information reasonably sufficient to allow us to locate the material.
You can contact us by making an issue.
Take down: We will comply to legitimate requests by removing the affected sources from the next release of the corpus.